
实验3 函数与代码复用
目的:理解函数封装与递归思想
实验任务
1.基础:编写函数cal_factorial(n)计算阶乘(循环实现)。
2.进阶:用递归实现斐波那契数列(考虑添加缓存优化)。
3.拓展:科赫曲线正向、反向绘制,加入绘制速度、绘制颜色等额外功能
提示:递归函数需注意终止条件,避免栈溢出
实验内容及结果
任务一:循环实现阶乘
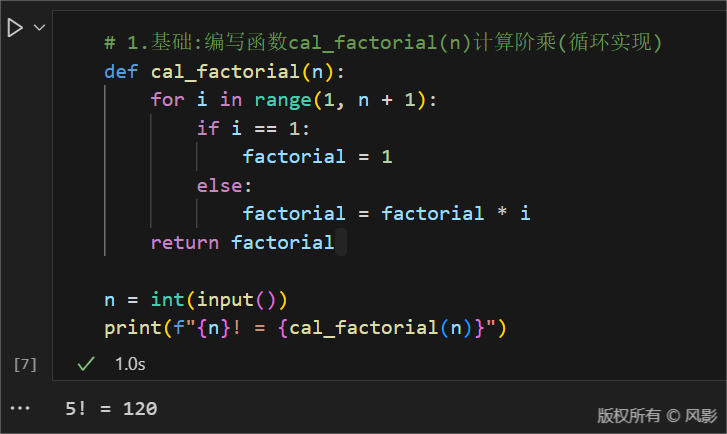
编写简单循环函数来实现阶乘,代码如下:
# 计算阶乘的函数
def cal_factorial(n):
for i in range(1, n + 1): # 遍历从 1 到 n 的每个整数
if i == 1:
factorial = 1 # 初始化:1 的阶乘为 1
else:
factorial = factorial * i # 累乘:阶乘 = 上一步结果 × 当前 i
return factorial # 返回最终结果
# 从用户输入获取 n 的值
n = int(input())
# 输出 n 的阶乘结果
print(f"{n}! = {cal_factorial(n)}")结果如下:
任务二:记忆化递归实现斐波那契数列
任务要求用递归实现斐波那契数列(考虑添加缓存优化),则采用记忆化递归的方式进行对结果的存储,使用到了字典,代码如下:
# 使用递归并结合缓存(记忆化)优化计算斐波那契数列
def fib(n, memo={}):
# 如果结果已缓存,直接返回(避免重复计算)
if n in memo:
return memo[n]
# 斐波那契数列的前两个基础值
if n <= 1:
return n
# 递归计算,并缓存结果
memo[n] = fib(n - 1, memo) + fib(n - 2, memo)
return memo[n]
for i in range(10):
print(fib(i), end=' ')为了直观感受添加记忆化递归比正常方法快了多少,我添加了计数器功能进行比较,代码如下:
import time
# 普通递归版(无优化)
def fib_plain(n):
if n <= 1:
return n
return fib_plain(n - 1) + fib_plain(n - 2)
# 记忆化递归版(缓存优化)
def fib_memo(n, memo={}):
if n in memo:
return memo[n]
if n <= 1:
return n
memo[n] = fib_memo(n - 1, memo) + fib_memo(n - 2, memo)
return memo[n]
# 测试用例
n = 35
# 计时:普通递归
start_plain = time.time()
result_plain = fib_plain(n)
end_plain = time.time()
print(f"[普通递归] fib({n}) = {result_plain},耗时 {end_plain - start_plain:.6f} 秒")
# 计时:记忆化递归
start_memo = time.time()
result_memo = fib_memo(n)
end_memo = time.time()
print(f"[记忆化递归] fib({n}) = {result_memo},耗时 {end_memo - start_memo:.6f} 秒")运行结果如下:

任务三:科赫曲线绘制
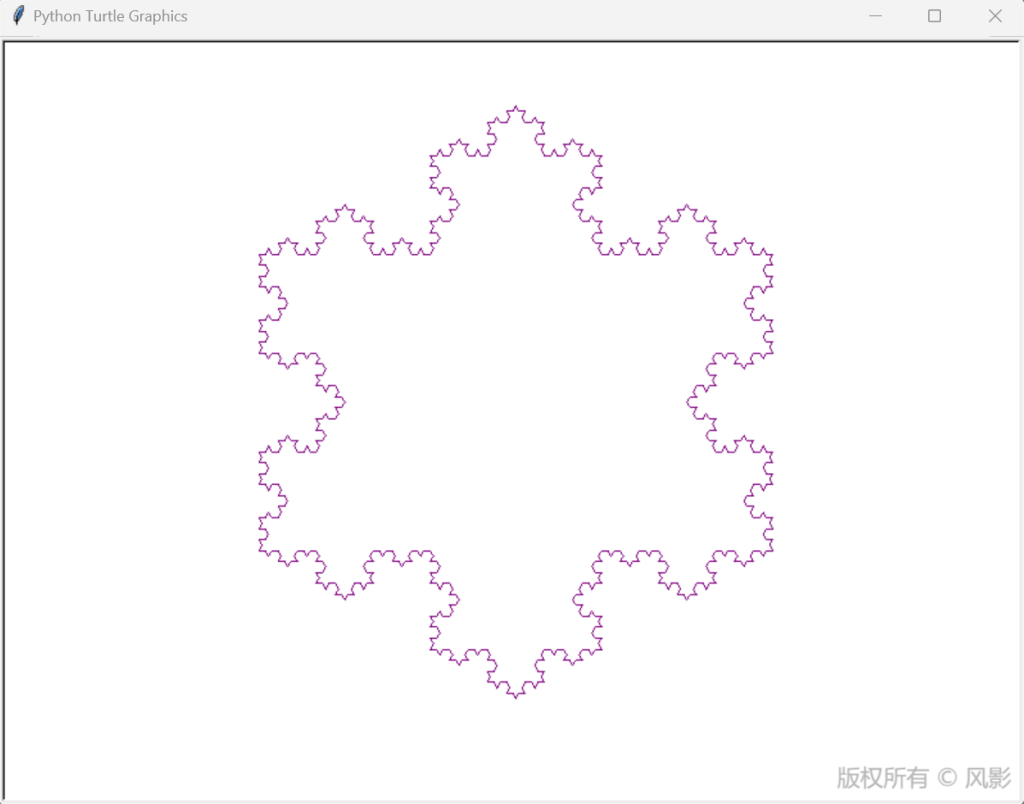
任务三要求为科赫曲线正向、反向绘制,加入绘制速度、绘制颜色等额外功能,科赫曲线是一种经典的分形图形,通过将线段不断等分并在中间插入等边三角形的方式递归生成。科赫曲线的经典拓展形式就是 科赫雪花(Koch Snowflake),代码如下:
import turtle
# 科赫曲线绘制函数
def koch_curve(t, length, level):
if level == 0:
t.forward(length)
else:
length /= 3.0
koch_curve(t, length, level - 1)
t.left(60)
koch_curve(t, length, level - 1)
t.right(120)
koch_curve(t, length, level - 1)
t.left(60)
koch_curve(t, length, level - 1)
# 主绘图函数
def draw_koch_snowflake(length=400, level=4, color="purple", speed=0):
turtle.setup(800, 600)
t = turtle.Turtle()
t.hideturtle()
t.speed(speed) # 0 为最快速绘制
t.color(color)
# 起始位置平移
t.penup()
t.goto(-length / 2, length / 3)
t.pendown()
# 绘制闭合的三条边,形成雪花
for _ in range(3):
koch_curve(t, length, level)
t.right(120)
turtle.done()
# 调用函数开始绘制
draw_koch_snowflake()运行结果如下:
实验4 列表与字典应用
目的:熟练操作组合数据类型。
实验任务
1.基础:生日悖论分析。如果一个房间有23人或以上,那么至少有两个人的生日相同的概率大于50%。编写程序,输出在不同随机样本数量下,23个人中至少两个人生日相同的概率。
2.进阶:统计《一句顶一万句》文本中前10高频词,生成词云。
3.拓展:金庸、古龙等武侠小说写作风格分析。输出不少于3个金庸(古龙)作品的最常用10个词语,找到其中的相关性,总结其风格。
实验内容及结果
任务一:生日悖论分析
生日悖论中说明,在仅有23人的群体中,至少两人生日相同的概率就超过50%。可以通过蒙特卡洛模拟法来验证:随机生成23人的生日(假设一年有365天,忽略闰年),重复实验多次,统计其中有重复生日的比例,即为概率估计值。通过不同的模拟次数(如100、1000、10000)观察概率的收敛趋势。代码如下:
# 任务一:生日悖论分析
import random
# 判断是否有重复生日
def has_duplicate_birthdays(num_people=23):
birthdays = [random.randint(1, 365) for _ in range(num_people)]
return len(set(birthdays)) < num_people
# 蒙特卡洛模拟估计概率
def estimate_probability(num_simulations):
count = 0
for _ in range(num_simulations):
if has_duplicate_birthdays():
count += 1
return count / num_simulations
# 测试不同样本数量
for simulations in [100, 1000, 10000, 100000]:
probability = estimate_probability(simulations)
print(f"模拟次数: {simulations} 次,23人中至少两人生日相同的概率 ≈ {probability:.4f}")测试结果最后趋向于0.5:

任务二:词云图
统计《一句顶一万句》文本中前10高频词,生成词云,我使用 jieba 对一段书中文本进行中文分词,过滤常见停用词,再统计词频并用 wordcloud 生成词云,最终展示前10个高频词以辅助理解文本核心内容。代码如下:
import jieba
from collections import Counter
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 文本内容(节选风格)
text = """
牛爱国这一辈子说的话比别人少,但记在心里的多。他不爱解释,也不爱争,别人不信他,他就让事实慢慢证明。
“话,是说给人听的,不是说给自己听的。”他爹总这么说,可是牛爱国觉得,有时候一句话,顶一万句。
牛爱国和杨百顺是一个村的,从小一块长大。杨百顺能说会道,人缘好,啥事儿都摆得平,村里人有事儿就找他。
可牛爱国只说必要的话,说一句,顶一万句。后来,两人走上不同的路,一个成了村主任,一个去了城里打工。
杨百顺坐在炕头唠家常,牛爱国坐在角落听他说。其实,听的人比说的人多,话少的人,心里反而装得多。
很多事,不用说。该说的时候,说一句就够了。
一句劝,一个转念,一辈子就这么过去了。
人这辈子,说得太多,往往是因为没人听懂他那一句。
"""
# 简化版中文停用词表
stopwords = set([
"的", "了", "和", "也", "就", "都", "是", "不", "在", "他", "她", "有", "人", "说",
"一个", "这", "那", "上", "中", "下", "为", "着", "从", "而", "对", "被", "以",
"但", "比", "又", "还", "很", "呢", "吧", "啊", "吗", "啊", "哦", "吧", "而且", "因为"
])
# 中文分词处理
words = jieba.lcut(text)
filtered_words = [word for word in words if word not in stopwords and len(word) > 1]
# 统计词频
word_counts = Counter(filtered_words)
top_10 = word_counts.most_common(10)
# 输出前10高频词
print("前10高频词:")
for word, count in top_10:
print(f"{word}: {count} 次")
# 生成词云
wc = WordCloud(
font_path="simhei.ttf",
width=800,
height=400,
background_color="white"
).generate_from_frequencies(word_counts)
# 显示词云
plt.figure(figsize=(10, 5))
plt.imshow(wc, interpolation="bilinear")
plt.axis("off")
plt.show()结果如下:

任务三:金庸(古龙)作品风格
任务三为拓展,金庸、古龙等武侠小说写作风格分析。输出不少于3个金庸(古龙)作品的最常用10个词语,找到其中的相关性,总结其风格。
金庸的武侠小说注重人物成长与道义冲突,语言细腻、节奏平稳,常围绕“忠义”“家国”“门派恩仇”展开,人物关系复杂而清晰,代表作如《射雕英雄传》《神雕侠侣》以大历史背景与传统价值构筑正义叙事。相比之下,古龙的小说则更具现代感与哲思色彩,讲求快节奏、强情节反转与心理描写,常以孤独、宿命、悬疑为主题,如《多情剑客无情剑》《楚留香新传》皆展现江湖人的孤傲与疏离。两者的风格形成鲜明对比:金庸构建“江湖世界”,古龙创造“人心江湖”。
我通过摘录金庸(古龙)作品的精彩片段,然后提取高频词以总结风格,最终绘制词云图,代码如下:
import jieba
from collections import Counter
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 金庸作品文本
jin_yong_texts = {
"射雕英雄传": """
郭靖生性朴实,重情重义,虽资质平平,却凭勤奋刻苦终成大侠。他与黄蓉并肩闯荡江湖,师承丐帮帮主洪七公,武功大进。
桃花岛风景秀丽,却也是武林纷争之地。江南七怪,欧阳锋,梅超风等人物纷纷登场,恩怨情仇逐渐展开。
郭靖道:“男子汉当为国为民,死亦无憾!”黄蓉浅笑,“你若死了,我便随你而去。”洪七公大笑,道:“好徒儿!”
""",
"神雕侠侣": """
杨过孤儿出身,聪慧倔强,入古墓派与小龙女相识相知。两人心意相通,却遭世俗眼光压迫。神雕助他,内力大进。
金轮法王、郭靖、黄蓉等在襄阳奋战保家卫国。杨过挥剑断臂,守义守爱,百般磨难终成大侠。
""",
"倚天屠龙记": """
张无忌幼年多舛,九阳真经疗伤救命。明教、六大派、倚天剑屠龙刀,天下武功谁与争锋?
赵敏刁蛮聪慧,周芷若深情而变。恩怨难清,情仇交织。
张无忌道:“我只想与心爱之人共度余生。”江湖却不容他平静。
"""
}
# 古龙作品文本
gu_long_texts = {
"多情剑客无情剑": """
李寻欢,一柄飞刀,例不虚发。沉默寡言,满身伤痛,却总为情所困。林诗音早已嫁人,阿飞影随形,冷眼旁观江湖恩怨。
龙啸云假义兄之名,实藏祸心。江湖多情,却也无情。
李寻欢轻叹:“飞刀一出,情断义绝。”阿飞望月无言,唯有孤独伴他左右。
""",
"绝代双骄": """
花无缺风度翩翩,小鱼儿机智滑稽,双生而异命。铁心兰情意难舍,江别鹤步步设局。
两人江湖重逢,既为兄弟,亦为宿敌。笑泪交织,命运捉弄。
小鱼儿道:“我只愿活得快意,哪管天下笑我。”花无缺眼含泪,“你若不是我兄弟,我便杀你。”
""",
"楚留香新传": """
楚留香轻功无双,风流倜傥,专破奇案。胭脂、红袖、盗宝、谜案相随,江湖夜话,处处玄机。
谜团之中藏情仇,美人之笑亦是假面。楚留香淡然道:“真相或许伤人,但我总得找出它。”
他仰望星空:“夜有尽时,江湖无尽。”
"""
}
# 停用词表
stopwords = set([
"的", "了", "和", "是", "就", "在", "不", "也", "有", "人", "他", "她", "我", "你", "说",
"着", "到", "去", "来", "啊", "吗", "都", "被", "这", "那", "一个", "上", "下", "道",
"便", "无", "与", "而", "却", "只", "为", "还", "总", "亦", "早", "已", "中", "中"
])
# 处理金庸文本:分词、过滤停用词
def get_word_freq(texts):
combined_text = " ".join(texts.values())
words = jieba.lcut(combined_text)
filtered_words = [w for w in words if w not in stopwords and len(w) > 1]
return Counter(filtered_words)
# 计算金庸和古龙的高频词
jin_yong_word_freq = get_word_freq(jin_yong_texts)
gu_long_word_freq = get_word_freq(gu_long_texts)
# 输出金庸和古龙的前10高频词
print("金庸作品前10高频词:", jin_yong_word_freq.most_common(10))
print("古龙作品前10高频词:", gu_long_word_freq.most_common(10))
# 生成金庸作品的词云
wc_jin_yong = WordCloud(font_path="simhei.ttf", background_color="white", width=800, height=600)
wc_jin_yong.generate_from_frequencies(jin_yong_word_freq)
plt.figure(figsize=(10, 8))
plt.imshow(wc_jin_yong, interpolation="bilinear")
plt.axis("off")
plt.title("金庸作品风格词云")
plt.show()
# 生成古龙作品的词云
wc_gu_long = WordCloud(font_path="simhei.ttf", background_color="white", width=800, height=600)
wc_gu_long.generate_from_frequencies(gu_long_word_freq)
plt.figure(figsize=(10, 8))
plt.imshow(wc_gu_long, interpolation="bilinear")
plt.axis("off")
plt.title("古龙作品风格词云")
plt.show()代码输出的前十高频词为:
金庸作品前10高频词: [(‘黄蓉’, 3), (‘郭靖’, 2), (‘终成’, 2), (‘大侠’, 2), (‘洪七公’, 2), (‘武功’, 2), (‘大进’, 2), (‘恩怨’, 2), (‘情仇’, 2), (‘杨过’, 2)]
古龙作品前10高频词: [(‘江湖’, 5), (‘李寻欢’, 2), (‘飞刀’, 2), (‘阿飞’, 2), (‘花无缺’, 2), (‘小鱼儿’, 2), (‘兄弟’, 2), (‘楚留香’, 2), (‘一柄’, 1), (‘虚发’, 1)]
二者的风格词云图如下所示:







